



Мишин Лернинг 🇺🇦🇮🇱
Субъективный канал об искусстве машинного обучения, нейронных сетях и новостях из мира искусственного интеллекта. Related channels | Similar channels
8 098
subscribers
Popular in the channel

🤯 Я сейчас не шучу, Дональд Трамп сгенерировал видео и выложил на своей платформе Truth Social. К...
✳️ Claude 3.7 Sonnet доступна всем! Anthropic представили Claude 3.7 Sonnet (лучшую на этой неде...
Трансляция GPT-4.5 Pro — скоро Plus юзеры — следующая неделя Основная мысль: очень много претр...
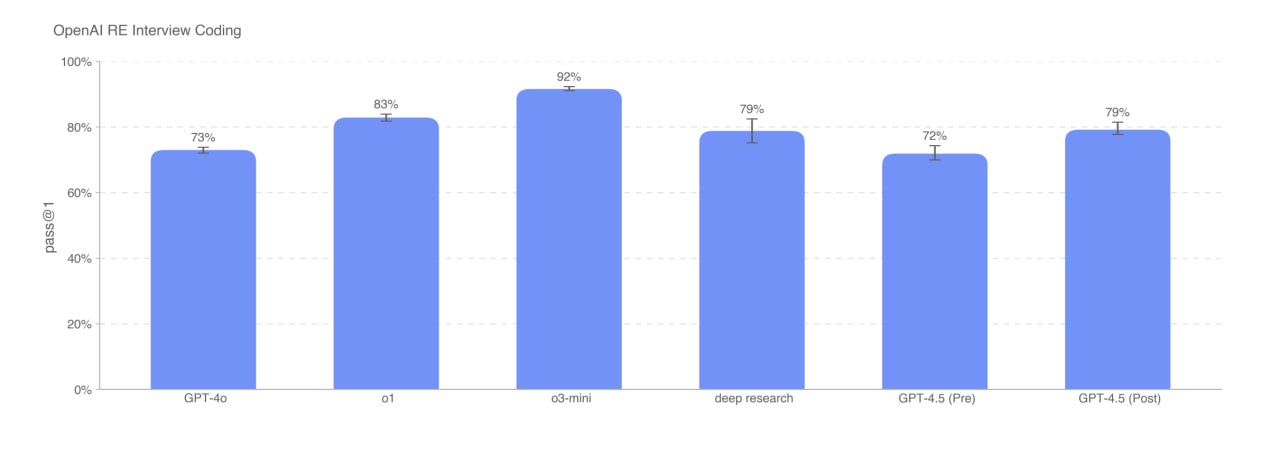
📄 Вышла системная карточка GPT-4.5 https://cdn.openai.com/gpt-4-5-system-card.pdf Если коротко,...
Подписчик пишет, что уже получил доступ к GPT-4.5 в подписке plus https://chatgpt.com/?model=gpt...