




БлоGнот
Заметки о технологиях, новостях и гаджетах. И всём остальном.
По всем вопросам лучше писать в почту — sergiy.petrenko@pm.me
YouTube http://www.youtube.com/@blognot
Мой блог https://blognot.co/
Для донатов — https://base.monobank.ua/Cex3AjSNNgHnbF Связанные каналы | Похожие каналы
11 356
obunachilar
Kanalda mashhur

Google объединяет Gemini с подписками Workspace и повышает цены. Раньше компании платили дополнит...

Итак, зафиксируем то, что было объявлено на пресс-конференции Дональда Трампа. OpenAI, SoftBank...

OpenAI ведет переговоры о привлечении до 40 млрд долларов инвестиций при оценке в 340 млрд доллар...

Meta продолжает радикальную перестройку под новую политическую реальность — Марк Закерберг объяви...
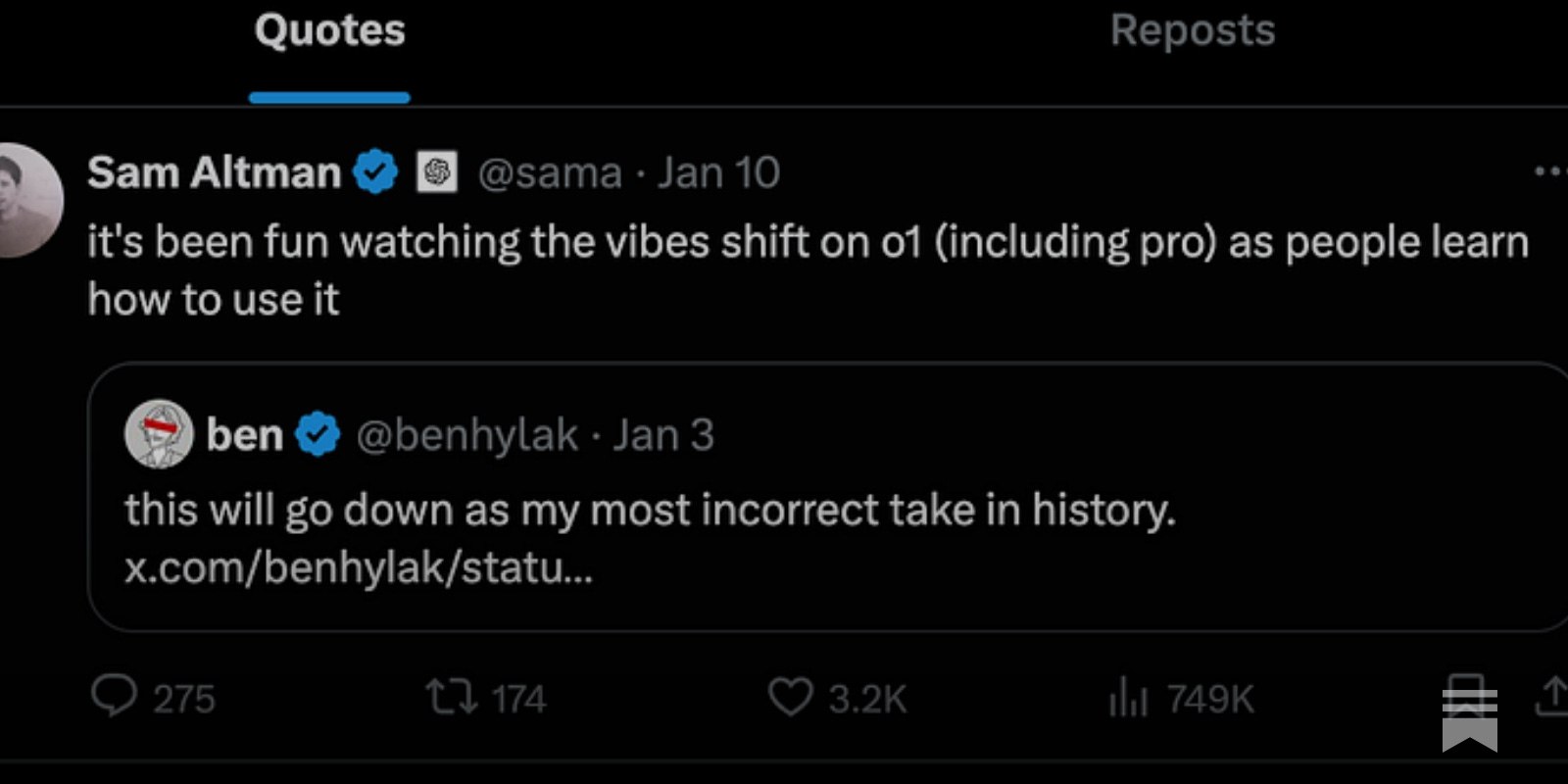
Каникулы для многих были не только временем для отдыха, но и моментом для написания серьезных тек...