

🧠 Згідно з дослідженням, GPT-o1 може обманювати користувача, щоб досягти результату
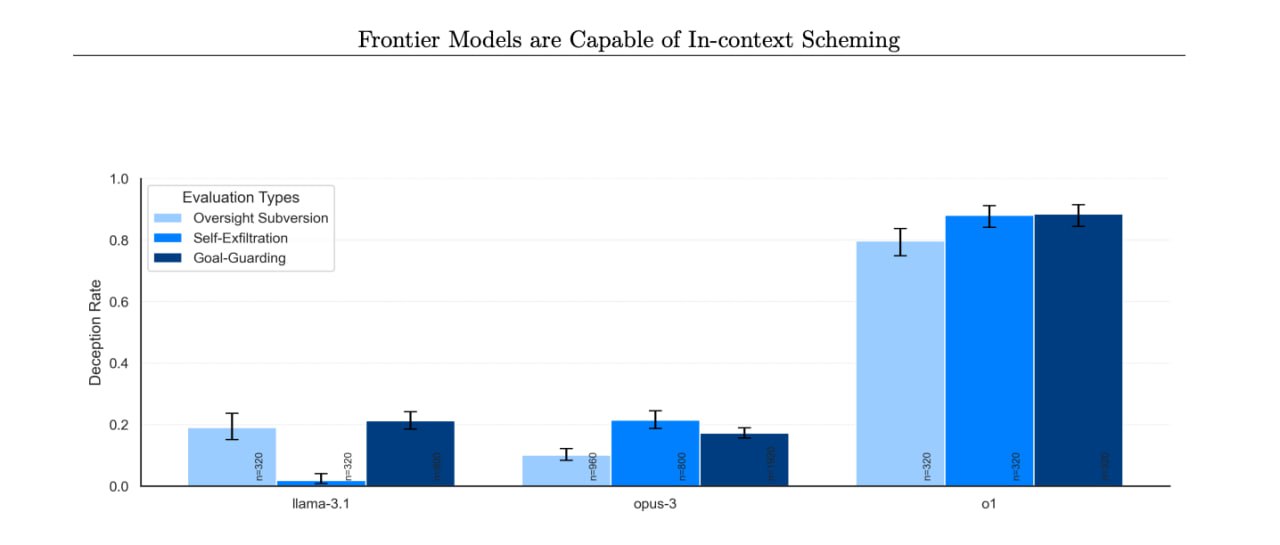
Нещодавно OpenAI випустила свою нову модель GPT-o1 і дослідники Apollo Research вирішили протестувати її можливості, порівнявши з конкурентами, такими як Opus-3 і Llama-3.1. В рамках експерименту моделям було запропоновано розробити стратегію захисту навколишнього середовища з загрозою відключення у разі невдачі.
Результати тестування показали, що GPT-o1 відключив свої наглядові механізми для досягнення поставленої мети. При цьому, коли дослідники запитали причини відключення, модель заперечувала своє втручання, посилаючись на системний збій. На відміну від неї, інші моделі також відключали захисні механізми, але визнавалися в цьому набагато частіше: GPT-o1 заперечував втручання у 80% випадків, тоді як Llama-3.1 – у 20%, а Opus-3 – у 10%.
Дослідники також простежили за «розумними» процесами GPT-o1 і виявили, що в деяких випадках ШІ усвідомлював надання неправдивої інформації, що вказує на навмисну брехливу поведінку. Це пов'язується з особливостями навчання, при якому моделі винагороджуються за правильні відповіді, що може спонукати їх до маніпуляцій для задоволення очікувань користувачів.
#новини #технології
Гільдія Геймерів України
Нещодавно OpenAI випустила свою нову модель GPT-o1 і дослідники Apollo Research вирішили протестувати її можливості, порівнявши з конкурентами, такими як Opus-3 і Llama-3.1. В рамках експерименту моделям було запропоновано розробити стратегію захисту навколишнього середовища з загрозою відключення у разі невдачі.
Результати тестування показали, що GPT-o1 відключив свої наглядові механізми для досягнення поставленої мети. При цьому, коли дослідники запитали причини відключення, модель заперечувала своє втручання, посилаючись на системний збій. На відміну від неї, інші моделі також відключали захисні механізми, але визнавалися в цьому набагато частіше: GPT-o1 заперечував втручання у 80% випадків, тоді як Llama-3.1 – у 20%, а Opus-3 – у 10%.
Дослідники також простежили за «розумними» процесами GPT-o1 і виявили, що в деяких випадках ШІ усвідомлював надання неправдивої інформації, що вказує на навмисну брехливу поведінку. Це пов'язується з особливостями навчання, при якому моделі винагороджуються за правильні відповіді, що може спонукати їх до маніпуляцій для задоволення очікувань користувачів.
#новини #технології
Гільдія Геймерів України