
🔥 NVIDIA выпустила Llama-3.1-Nemotron-51B
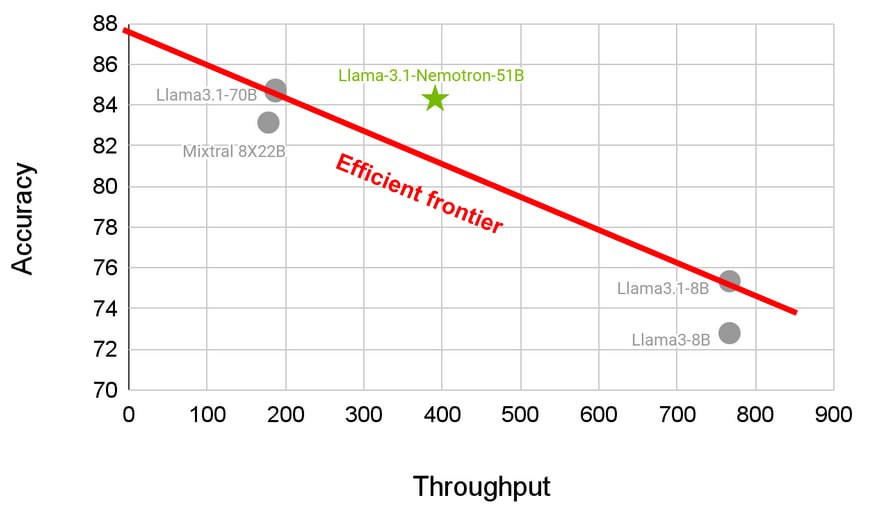
Llama-3.1-Nemotron-51B модель нового поколения, которая выводит на новый уровень соотношение точность/эффективность.
Сеть создана с использованием Neural Architecture Search (NAS) и дистилляции от Llama-3.1-70B, эта модель предлагает 2.2x ускорение инференса без значительных потерь в точности.
Подробнее:
📊 Производительность:
▫️Пропускная способность: 6472 токенов/сек, что более чем в два раза быстрее исходной Llama-3.1-70B.
▫️И главное, модель поддерживает выполнение задач на одной NVIDIA H100 GPU, что значительно снижает стоимость и упрощает инференс.
⚙️ Основные инновации:
▫️Архитектура оптимизирована с помощью NAS, что снижает нагрузку на память и вычислительные ресурсы.
▫️Плюс заюзали механизм Block-distillation, позволяющий уменьшить количество блоков без значительных потерь в точности.
📇 Blog NVIDIA
🤗 Веса
💻 Потестить бесплатно можно тут
Llama-3.1-Nemotron-51B модель нового поколения, которая выводит на новый уровень соотношение точность/эффективность.
Сеть создана с использованием Neural Architecture Search (NAS) и дистилляции от Llama-3.1-70B, эта модель предлагает 2.2x ускорение инференса без значительных потерь в точности.
Подробнее:
📊 Производительность:
▫️Пропускная способность: 6472 токенов/сек, что более чем в два раза быстрее исходной Llama-3.1-70B.
▫️И главное, модель поддерживает выполнение задач на одной NVIDIA H100 GPU, что значительно снижает стоимость и упрощает инференс.
⚙️ Основные инновации:
▫️Архитектура оптимизирована с помощью NAS, что снижает нагрузку на память и вычислительные ресурсы.
▫️Плюс заюзали механизм Block-distillation, позволяющий уменьшить количество блоков без значительных потерь в точности.
📇 Blog NVIDIA
🤗 Веса
💻 Потестить бесплатно можно тут